POSIX 线程
满足 POSIX 线程标准的线程就是 POSIX 线程,POSIX 线程标准中定义了一套用于创建和操纵线程的 API。在 C Unix 平台上使用 POSIX 线程可以包含 pthread.h 这个头文件。很多高级语言都实现了对线程的封装,但是大多只是对 pthread.h 中接口的封装。
什么是线程
要说明什么是线程,还是先说说什么是进程吧。以前在学习操作系统的时候书上说一个程序启动后,操作系统会为其创建一个进程控制块。进程控制块里面包含很多信息,下面是部分感觉在概念上比较重要的:
- 进程 id:用于标识不同的进程
- 进程的状态:就绪、运行、挂起、停止
- 进程切换时寄存器的状态:当进程切换后,为了下次切换回来时能够继续运行,需要把 CPU 在切换前的寄存器状态保存下来
- 程序计数器:指向下一条指令的位置
- 虚拟地址空间的页表信息:虚拟地址和物理地址的映射情况
- 当前工作目录
- 打开的文件描述符
程序执行过程,就是从 PC(程序计数器)处取指令,然后执行这条指令。至于函数传参、函数调用等等,这都由编译器安排好了。CPU 只管从 PC 处取值,然后执行,然后修改 PC 的值,再此重复。因此,一个 PC 就是一个控制流。那么如果有多个 PC 呢,CPU 在多个核上从多个 PC 处取指令然后执行,这样一个进程中就有了多个控制流。
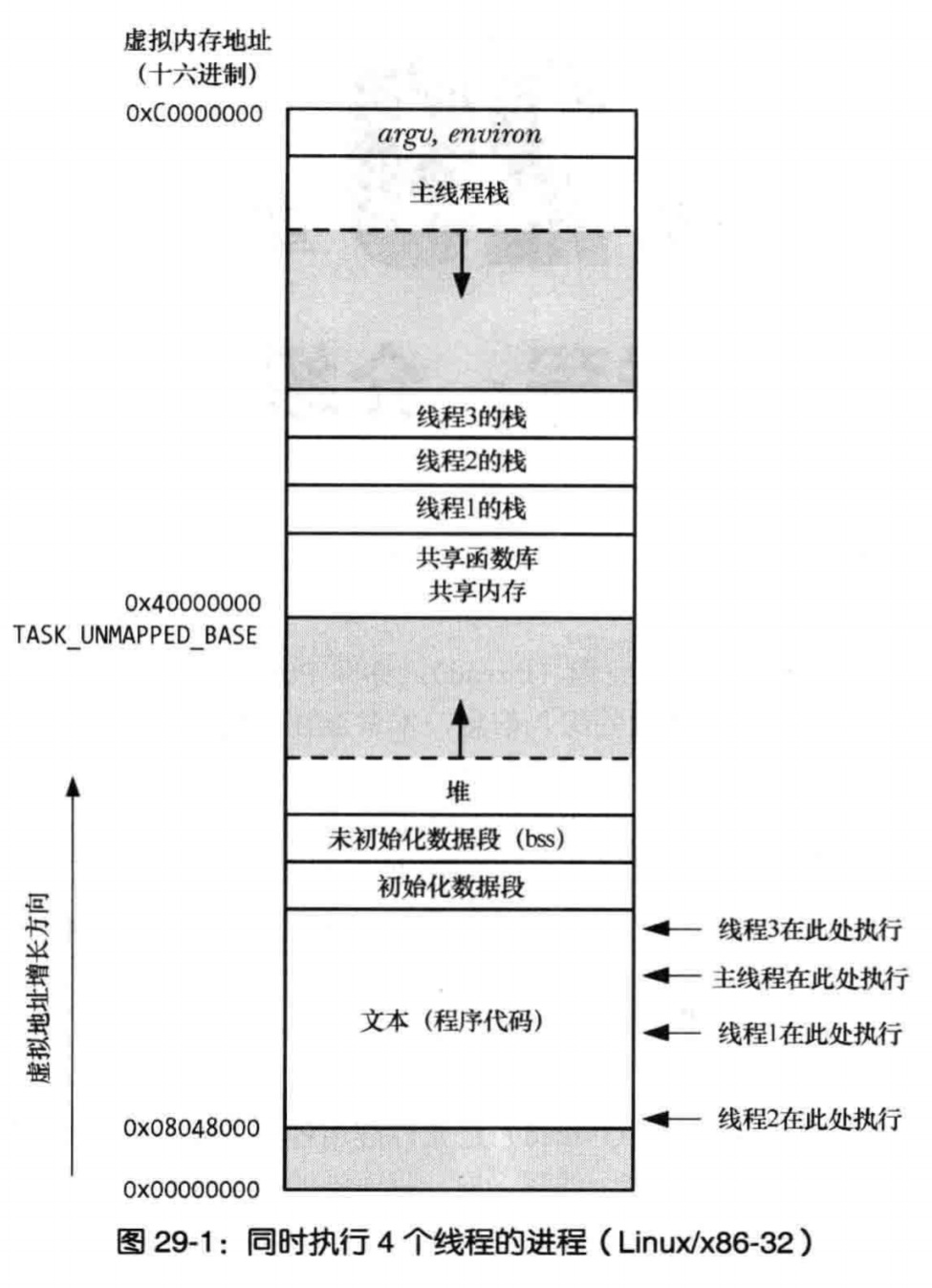
但是执行指令的时候,还需要有执行栈才行。但这有何难,在虚拟存储空间中,取一段内存作为不就可以了。什么是线程?我认为这就是线程,一个 PC,一个执行栈,就可以让一个进程中多出一个控制流,而线程就是这样的一个控制流。基于此,可以想象与线程关联的数据结构中,至少包含线程的 PC、线程的栈空间、线程的寄存器状态。
多个线程共享代码段,代码段没办法修改,这不存在什么问题。但是虚拟存储空间中的 .data 和 .bss 以及运行时堆,这是多个线程可以共享的。因此,线程之间存在竞争。
pthread 提供了创建和销毁线程的方法,同时提供了一套加锁的策略。
线程操作
创建线程
下面是个创建和取消线程的例子,主线程中(进程在未创建新的线程时就有一个线程,该线程叫做主线程,从 main 进入的那个控制流)创建了子线程,然后处于睡眠状态。子进程中每隔一秒打印一次。
#include <pthread.h>
#include <cstdio>
#include <unistd.h>
void* print(void *arg) {
const char* text = static_cast<const char*>(arg);
while (true){
sleep(1);
printf("%s\n", text);
}
}
int main() {
pthread_t t;
const char* text = "hello";
pthread_create(&t, nullptr, print, (void *) text);
sleep(20);
pthread_cancel(t);
}
pthread_t 是线程 id 的数据类型。它通常是 long,但是不建议作此假设。判断两个线程 id 是否相同,需要使用 pthread_equal(t1, t2)。获取当前线程的线程 id 可以使用 pthread_self()。
pthread_create 用来创建一个线程,线程的入口是某个函数,这和进程的入口是主函数很类似。同时可以给函数传入参数,因为传入的参数五花八门,这里接受的参数是一个 void* 这样就可以将任何类型的数据传递给线程了。
取消线程
使用线程号,可以使用 pthread_cancel 取消某一线程。
int pthread_cancel (pthread_t thread);
某一线程 A 正在运行,现另有一个线程想要取消线程 A,即停止线程 A 的运行。A 线程进行着取指-执行的循环,并不知道某线程希望自己停止下来。要想终止,需要有操作系统的介入,比如操作系统周期性检查各个线程是否需要被取消。即便如此,想要在发出取消请求后立刻取消指定线程的执行,这存在一些困难。因为此时线程一直在取值-执行,此时 CPU 被用户代码接管,直到下次线程切换时操作系统才能插手。
线程的取消,发生在取消点上。取消点,其实就是操作系统有机会调度该线程的时候,当操作系统调度该线程的时候,发现该线程被请求取消,这时候就可以果断取消之。
某些系统调用被规定必须为取消点函数,即在执行该函数的时候,线程有机会被取消。比如 open, sleep 等。纵观此类函数,其特点是调用它们之后,线程会被阻塞,操作系统此时又机会来调度该线程。此时,操作系统有机会取消该线程。
试想,如果某个线程中进行的是计算密集型的操作,那就没有取消点的存在了,为此可以人为地加入一个取消点。
#include <pthread.h>
#include <cstdio>
#include <climits>
void* func(void *arg) {
long n = 0;
for (int i = 0; i < INT_MAX; i++) {
n += 1;
}
printf("%ld\n", n);
}
int main() {
pthread_t t1;
pthread_create(&t1, nullptr, func, nullptr);
pthread_cancel(t1);
pthread_join(t1, nullptr);
}
上面这段代码,主线程创建子线程后立刻尝试取消,但是大约 6 秒后,子线程中打印了结果,然后才退出。因为这个函数中没有取消点。
void* func(void *arg) {
long n = 0;
for (int i = 0; i < INT_MAX; i++) {
pthread_testcancel();
n += 1;
}
printf("%ld\n", n);
}
人为地增加一个取消点,当执行到 pthread_testcancel 时,如果该线程被请求取消,那就会在此处取消。
pthread_join 和 pthread_detach
前面的例子中,主线程中调用了 pthread_join(t1, nullptr),pthread_join 的作用是等待线程执行完毕。如果没有这行,主线程执行完毕后,进程就退出了。其他子线程自然也就退出了。第二个参数是一个指针的指针,用于线程的返回值。如果线程退出了,但是其返回值尚未被 pthread_join 接收,那么它占用的资源就不会被释放。调用了 pthread_join(t1, nullptr) 的线程会阻塞,直到 t1 线程退出为止。
pthread_detach 用于指出不关心线程的返回值,在线程结束时,操作系统自动清理。一旦分离的之后,就不能再调用 pthread_join 来获取状态了。
清理函数
考虑下面这段代码,如果在执行 malloc 之后 free之前,线程遭遇取消,那么 buf 就无法释放,这将引起内存泄漏。
void* func(void *arg){
const int LEN = 30;
char *buf = (char*)malloc(LEN);
read(STDIN_FILENO, buf, LEN);
write(STDOUT_FILENO, buf, LEN);
free(buf);
}
下面是改进方法,pthread_cleanup_push 接受一个函数将其入栈,在线程取消后,会依次将函数出栈,并执行这些函数。另外可以使用 pthread_cleanup_pop 显式地将一个函数出栈,在出栈的时候可以指定其是否执行。
void* func(void *arg){
const int LEN = 30;
char *buf = (char*)malloc(LEN);
pthread_cleanup_push(free, buf);
read(STDIN_FILENO, buf, LEN);
write(STDOUT_FILENO, buf, LEN);
pthread_cleanup_pop(1);
}
上面这段代码,如果在没有遭遇取消,那么在 pthread_cleanup_pop 的时候,就会出栈并执行释放内存的函数。如果遭到了取消,那么操作系统会调用 pthread_cleanup_push 添加的函数,也会完成清理工作。
pthread_cleanup_push 和 pthread_cleanup_pop 是两个宏,观察它们的定义就会明白,它两要成对出现。否则宏展开后会 do while 语句就不闭合。
#define pthread_cleanup_push(routine, arg) \
do { \
__pthread_cleanup_class __clframe (routine, arg)
#define pthread_cleanup_pop(execute) \
__clframe.__setdoit (execute); \
} while (0)
为什么能在线程退出时候,执行先前入栈的清理函数呢,因为 pthread_cleanup_push 创建了一个对象,该对象的析构函数会执行清理函数。线程提前退出时,对象会被析构。
class __pthread_cleanup_class {
void (*__cancel_routine)(void *);
void *__cancel_arg;
int __do_it;
int __cancel_type;
public:
__pthread_cleanup_class(void (*__fct)(void *), void *__arg)
: __cancel_routine(__fct), __cancel_arg(__arg), __do_it(1) {}
~__pthread_cleanup_class() { if (__do_it) __cancel_routine(__cancel_arg); }
void __setdoit(int __newval) { __do_it = __newval; }
void __defer() {
pthread_setcanceltype(PTHREAD_CANCEL_DEFERRED, &__cancel_type);
}
void __restore() const { pthread_setcanceltype(__cancel_type, 0); }
};
基于以上了解,应该清楚地知道,不应该写出如下代码:
if(cond){
pthread_cleanup_pop(0);
}
线程同步
既然线程之间存在数据竞争,这就需要引入锁机制。
互斥锁
互斥锁用来创建临界区。如果试图对已经上锁的互斥锁进行上锁,将会阻塞。下面是一个简单的例子:
#include <pthread.h>
#include <cstdio>
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
int num = 0;
void* func(void *arg) {
int n = *static_cast<int*>(arg);
for (int i = 0; i < 50000; i++) {
pthread_mutex_lock(&lock);
num += n;
pthread_mutex_unlock(&lock);
}
return nullptr;
}
int main() {
pthread_t t1, t2;
int n = 1;
pthread_create(&t1, nullptr, func, &n);
pthread_create(&t2, nullptr, func, &n);
pthread_join(t1, nullptr);
pthread_join(t2, nullptr);
printf("%d\n", num); // 100000
return 0;
}
上面的代码中静态初始化了一个互斥量,初始的方法为赋值 PTHREAD_MUTEX_INITIALIZER。如果是动态分配,则需要调用 pthread_mutex_init 来初始化。此互斥量不再使用时,使用 pthread_mutex_destroy 销毁。这里的销毁并不是释放内存空间,而是销毁互斥量内部实现的某些东西。
条件变量
在生产者消费者场景中,假设有 10 个生产者,1 个消费者,生产者在不同的线程运行,消费者在主线程。
已经生产的数量,在这些线程中存在竞争。因此在访问该变量的时候需要使用一个互斥锁。在消费者线程中,它需要检查当前是否有产品供它消费。
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
int avail = 0;
void* producer(void *arg){
while (true){
// 生产...
pthread_mutex_lock(&mtx);
avail += 1;
pthread_mutex_unlock(&mtx);
}
}
int main(){
for(int i=0;i<10;i++){
pthread_t t;
pthread_create(&t, nullptr, producer, NULL);
}
while(1){
pthread_mutex_lock(&mtx);
// 检查是否可以消费
if(avail > 0){
consume();
avail -= 1;
}
pthread_mutex_unlock(&mtx);
}
}
主线程一直在轮询,很浪费 CPU 时间。可以在主线程中加入休眠,但这样又无法及时进行消费。需要一种机制,能够让生产者来提示消费者。条件变量结合互斥锁能够提供这种机制。
pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
void* producer(void *arg){
while (true){
usleep(100);
pthread_mutex_lock(&mtx);
avail += 1;
pthread_mutex_unlock(&mtx);
pthread_cond_signal(&cond);
}
}
int main(){
for(int i=0;i<10;i++){
pthread_t t;
pthread_create(&t, nullptr, producer, nullptr);
pthread_detach(t);
}
while(1){
pthread_cond_wait(&cond, &mtx);
while(avail > 0){
// 消费
avail -= 1;
}
pthread_mutex_unlock(&mtx);
}
}
pthread_cond_wait 在一个条件变量上阻塞,当收到通知后,再对互斥锁加锁。在生产者线程中,可以使用 pthread_cond_signal 来发送信号给条件变量,这起到了通知的作用。基于条件变量的实现,不需要做轮询操作,生产者生产完成后会唤醒消费者。
另外信号并不能长期存在,如果在调用 pthread_cond_signal 的时候,并没有线程在等待信号,那么此信号就会消失。即假如所有生产者在消费者调用 pthread_cond_wait 之前就发出了信号。那么 pthread_cond_wait 会一直阻塞下去。
pthread_cond_wait 的执行步骤如下:
- 解锁互斥量 mutex
- 阻塞调用线程,知道在 cond 上收到信号
- 重新锁定 mutex
因此当 pthread_cond_wait 返回的时候,共享的变量是受互斥锁保护的。处理完成后,应该释放互斥锁。
pthread_cond_wait 调用范式
对 pthread_cond_wait 的调用通常采用下面这样的方式,而不是上面那段代码中的方法。不过上面那种方法在此场景下也没有问题。但是下面的写法根据通用且稳妥。
while(true){
pthread_mutex_lock(&mutex);
while(avail == 0){
pthread_cond_wait(&cond, &mutex);
}
while(avail > 0){
// 消费
avail--;
}
pthread_mutex_unlock(&mutex);
}
如果存在多个消费者,而且生产者使用了 pthread_cond_broadcast,这会同时唤醒多个消费者线程。某个消费者线程从 pthread_cond_wait 返回后,看似收到的信号,但是生产出来的物品可能已经被别的消费者消耗完了。
综上原因,需要在一个循环语句中调用 pthread_cond_wait,并在不满足条件时继续等待。由于第一个 while 语句用到了共享变量,因此需要先加互斥锁。
广播
如果有多个线程阻塞在条件变量上,可以使用 pthread_cond_broadcast 一次唤醒多个阻塞线程。
超时
用 pthread_cond_timedwait 可以指定一个阻塞的最长时间。
timeval tv;
timespec ts;
gettimeofday(&tv, NULL);
ts.tv_sec = tv.tv_sec + 2;
ts.tv_nsec = tv.tv_usec * 1000;
pthread_cond_timedwait(&cond, &mtx, &ts);
屏障
当一个线程需要等待多个线程时,屏障就很有用。
#include <pthread.h>
#include <unistd.h>
#include <cstdio>
pthread_barrier_t b;
void* func(void *arg) {
int second = *reinterpret_cast<int *>(&arg);
sleep(second);
printf("wait\n");
pthread_barrier_wait(&b);
printf("run\n");
}
int main() {
pthread_barrier_init(&b, nullptr, 6);
for (int i = 0; i < 5; i++) {
pthread_t t;
pthread_create(&t, nullptr, func, reinterpret_cast<void *>(i));
}
printf("wait\n");
pthread_barrier_wait(&b);
printf("run\n");
}
屏障将多个线程阻挡在一个屏障前,这些线程都运行到了屏障处后,所有线程可以通过屏障继续执行。
pthread_barrier_init 用来初始化一个屏障,设置屏障的属性,以及需要等待多少个线程。pthread_barrier_wait 表示一个线程已经到达屏障了,等待其他线程达到屏障。当多个线程都调用了 pthread_barrier_wait 后,到达屏障的线程数目等于先前设置好的数量时,所有线程可以从 pthread_barrier_wait 返回。
执行上面的示例,由于子线程中存在睡眠,wait 是逐个打印出来的。但是打印了 6 个后,run 会同时打印出来。
线程存储
线程特有数据
某些函数使用了全局变量来存储状态,如果多个线程同时使用这类函数,如果不采用锁机制,就会出现问题。如果一个函数只使用局部变量,该函数不依赖全局变量,多个线程就可以安全地使用该函数。
但某些函数必须使用全局变量,比如 strerror 函数:
char *strerror(int err);
该函数接受一个错误码,返回错误对应的字符串。再次调用该函数,返回的指针指向的内容就会被修改,因此多个线程同时使用该函数,就存在问题。试想,某个线程调用了该函数,正准备使用返回的结果,另一个线程又调用了该函数,全局的字符串被修改了。
{
"thread_1": {
"a": 1
},
"thread_2": {
"a": 2
}
}
试想,如果能够把全局空间用线程 id 来划分出多个子空间,然后这些使用全局变量的函数,利用当前的线程 id 在子空间中取变量,这样各个线程就不会冲突了。
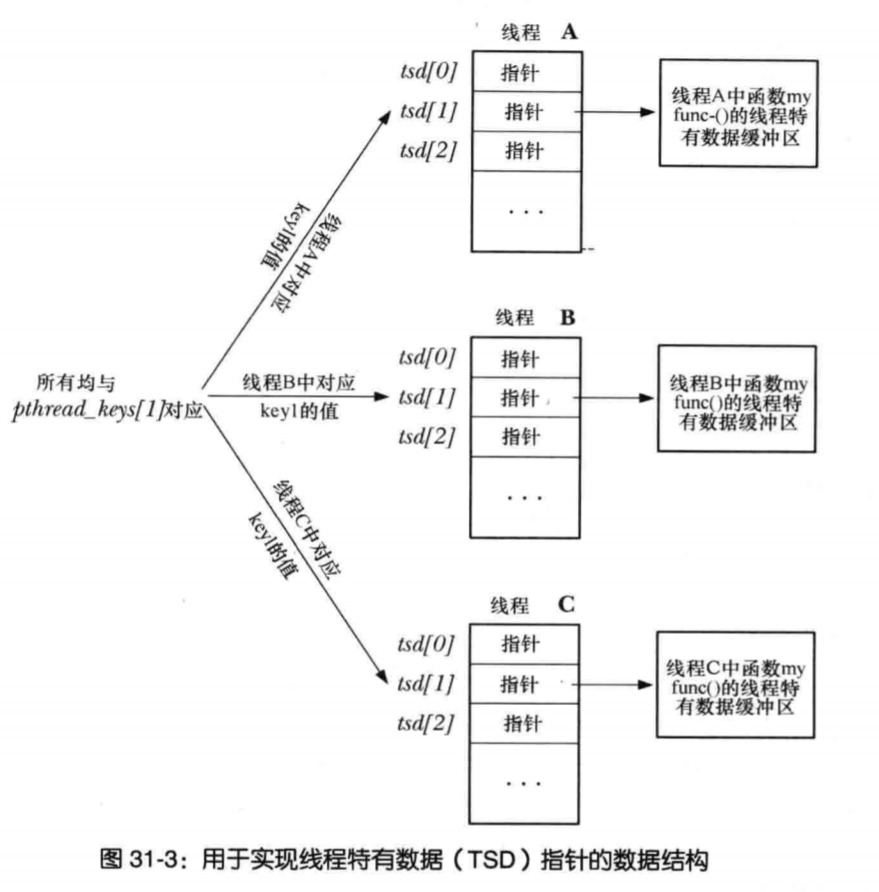
基于之前提到的思想,实现下面这个玩具函数,用于演示。该函数需要一个缓存区来存放结果字符串。在函数内部根据线程 id 和函数唯一的 KEY,在 global 中得到了该线程中该函数独享的指针。如果该指针为空,那就在堆上分配空间。随后可以使用这个线程和函数独享的内存做余下的事情。
#include <unordered_map>
std::unordered_map<int, std::unordered_map<int, void*>> global;
char* format(const char *fmt, ...){
int tid = (int)pthread_self();
const int MAX_LEN = 200;
const int KEY = 1;
if(!global[tid][KEY]){
global[tid][KEY] = malloc(MAX_LEN);
}
char *buf = (char*)global[tid][KEY];
va_list vp;
va_start(vp, fmt);
vsnprintf(buf, MAX_LEN, fmt, vp);
va_end(vp);
return buf;
}
以上的实现只用于说明一种思想,实际上存在一些问题:
- 函数中的这个 KEY 如何确定,如何保证在线程空间中唯一。
- 不知道在何时用何种方法释放内存
- 对全局变量的使用存在竞争
我们可以尝试解决以上问题:
#include <pthread.h>
#include <cstdio>
#include <cstdarg>
#include <unordered_map>
std::unordered_map<int, std::unordered_map<int, void*>> global;
pthread_mutex_t unique_key_mutex = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t global_mutex = PTHREAD_MUTEX_INITIALIZER;
// 创建唯一的 key
int create_unique_key(){
static int key = 0;
key++;
return key;
}
char* format(const char *fmt, ...){
// 每个全局变量都对应一个唯一的 key
pthread_mutex_lock(&unique_key_mutex);
static const int key = create_unique_key();
pthread_mutex_unlock(&unique_key_mutex);
// 当前线程的线程 id
int tid = (int)pthread_self();
const int MAX_LEN = 1024;
pthread_mutex_lock(&global_mutex);
// 在 global 空间中取出 key 对应的指针,如果不存在就动态分配空间
// 这里涉及到多个线程会竞争,因此需要加锁保护
if(!global[tid][key]){
global[tid][key] = malloc(MAX_LEN);
}
char *buf = (char*)global[tid][key];
pthread_mutex_unlock(&global_mutex);
// 这里 buf 就是该线程独有了
va_list vp;
va_start(vp, fmt);
vsnprintf(buf, MAX_LEN, fmt, vp);
va_end(vp);
return buf;
}
对每个需要使用的全局变量,都动态开辟空间,并且以 线程 id 和变量 id 为键值存储在一个 map 里,这样每个线程中的每个全局变量都有独立的一份,各个线程就互不影响了。
pthread 为线程特有数据提供了完善的解决方案,其思想和上面提到的差不多,但使用起来方便不少,下面是基于 pthread 相关接口实现的 format:
static pthread_key_t format_key;
static pthread_once_t format_once = PTHREAD_ONCE_INIT;
static void destructor(void *buf){
free(buf);
}
static void create_format_key(){
pthread_key_create(&format_key, destructor);
}
char* format(const char *fmt, ...){
const int MAX_LEN = 200;
pthread_once(&once, create_format_key);
void *ptr = pthread_getspecific(format_key);
if(ptr == nullptr){
const int MAX_LEN = 200;
ptr = malloc(MAX_LEN);
pthread_setspecific(format_key, ptr);
}
char *buf = static_cast<char*>(ptr);
va_list vp;
va_start(vp, fmt);
vsnprintf(buf, MAX_LEN, fmt, vp);
va_end(vp);
return buf;
}
代码中使用 pthread_once 保证传入的函数只执行一次,因为 key 只需要创建一次。为了保证创建 key 的代码只执行一次,可能写出如下代码:
static bool first = true;
if(first){
first = false;
pthread_key_create(&format_key, destructor);
}
但以上代码中,在 first = false 执行完成之前,其他线程也可能会进入 if 语句,因此需要加锁。而使用 pthread_once 并将只需要执行一次的代码写入一个函数,可以保证这些代码只会执行一次。即第一个执行到这里的线程会执行,此后任何线程都不再执行。
pthread_once(&once, create_format_key) 是将 once 和一个函数关联起来,另外 once 上还记录有执行的次数,每次运行到这一行代码时,会根据与 once 关联的执行次数来决定是否执行传入的函数。这里面涉及的竞争,都由该函数处理了。
pthread_setspecific 和 pthread_getspecific 则用于给 key 设置指针和从 key 上获取指针。
线程局部存储
如果一个函数依赖全局变量,由于多个线程中可能同时使用该全局变量,这导致全局变量可能被修改。如果能有一种办法,创建一个全局变量后,不同线程都有一份拷贝,就不存在竞争了。
这样的功能是存在的,存在一个非标准特性,在很多 Unix 实现中都包含此特性。在创建全局变量时,在前面加上 __thread,如此,不同的线程都会拥有这个变量的拷贝。
使用这特性改写前面的 format 的例子如下:
__thread char format_buffer[1024];
char* format(const char *fmt, ...) {
va_list vp;
va_start(vp, fmt);
vsnprintf(format_buffer, sizeof(format_buffer), fmt, vp);
va_end(vp);
return format_buffer;
}
线程实现模型
线程如何与内核调度实体相映射
- 多对一(用户级线程)
操作系统对进程中的多个线程并无感知,线程的创建、调度等细节由进程内用户空间的线程库来处理。内核无法调度多个线程,无法利用多核。
- 一对一(内核级线程)
每个线程映射一个单独的内核调度实体,内核能够对每个线程进行调度。一个线程阻塞的时候,其他线程依然可以得到调度。线程的创建、上下文切换等操作都需要在内核模式下进行。
- 多对多(两级模型)
每个进程拥有多个内核调度实体,进程可以将多个线程映射到对应的内核调度实体上。这一解决方案,支持将多个线程调度到不同的 CPU 去执行,同时也克服了线程数较多时候带来的性能问题。
POSIX 线程是一种标准,针对此标准有多种实现,在 GNU C 库中可能使用 LinuxThreads 和 NPTL 两种实现之一。我的机器 (Ubuntu 18.04) 上使用的是 NPTL 线程库,这是一个较 LinuxThreads 更新的线程库,采用一对一线程模型。
$ getconf GUN_LIBTHREAD_VERSION
NPTL 2.27